

Môže umelá inteligencia (AI) rozhodovať o prepustení niekoho z väzenia alebo o postupe do ďalšieho kola pracovného pohovoru? Môže odporúčať preventívne vyšetrenia alebo prevziať zodpovednosť za riadenie vozidla v snehovej búrke? Nie ste si istí, ako odpovedať na tieto otázky? Keby ste vedeli, že AI vie svoje rozhodnutie detailne zdôvodniť a každý človek si môže overiť, či sa rozhodovala správne – zmenilo by to váš názor?
V prvom diele série článkov na tému vysvetliteľnej a transparentnej umelej inteligencie sa budeme venovať tomu, prečo potrebujeme, aby bola umelá inteligencia vysvetliteľná a transparentná a ako hľadáme rovnováhu medzi presnosťou a interpretovateľnosťou.
Úvod do vysvetliteľnej AI
Aj keď zásluhou Warrena McCullocha a Waltera Pittsa poznáme neurónové siete už od roku 1943, ich najnovší boom, po ktorom získali dominanciu v rámci strojového učenia, sa začal až v roku 2012 výskumom Alexa Krizhevského, Ilyu Sutskevera a Geoffreyho Hintona, priekopníkov hlbokého učenia (deep learning) ako súčasnej dominantnej vetvy AI.
Vo svojej práci publikovanej pod názvom ImageNet classification with deep convolutional neural networks ukázali, že aj pomerne jednoduchá hlboká neurónová sieť, ktorá sa skladala z ôsmich vrstiev (v porovnaní so súčasnými sieťami, ktoré môžu obsahovať aj viac ako tisíc skrytých vrstiev) výrazným spôsobom prekonala vtedajšie prístupy pri klasifikácii obrázkov do tisícky rôznych tried.
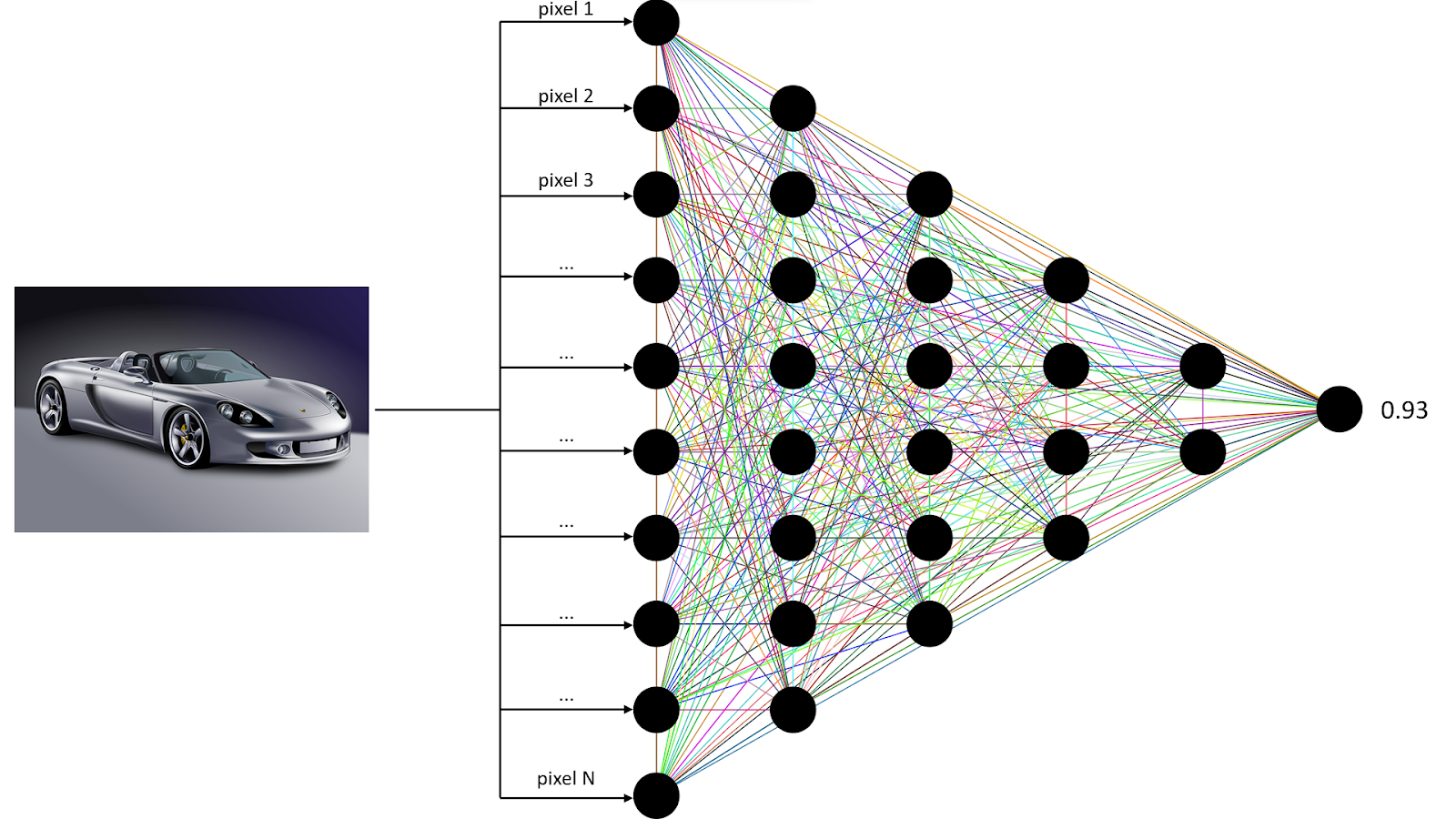
Typická jednoduchá neurónová sieť sa skladá zo vstupnej vrstvy, viacerých skrytých vrstiev a jednej výstupnej vrstvy. Vstupná vrstva predstavuje dáta, s ktorými neurónová sieť pracuje – môže ísť o hodnoty pixelov obrázka, číselnú reprezentáciu slov alebo hodnoty namerané senzorom. Skryté vrstvy následne tieto vstupy postupne transformujú na tzv. skrytú (alebo latentnú) reprezentáciu. V prípade obrázkov si takúto reprezentáciu môžeme predstaviť ako výsledok filtrovania obrázka v grafickom editore. Neuróny na výstupnej vrstve predstavujú finálnu predpoveď neurónovej siete.
Viac vrstiev, vyššia výkonnosť

Princíp fungovania moderných neurónových sietí je, zjednodušene povedané, založený na postupnom filtrovaní a transformovaní vstupných dát, až kým takto zmenená informácia nedá odpoveď na nejakú otázku, na ktorú má model odpovedať. Ak má napríklad model klasifikovať obrázky, tak v prvej skrytej vrstve môže vyfiltrovať či zvýrazniť hrany, rozmazať obrázok alebo v ňom zvýrazniť nejakú farbu – alebo všetko naraz.
Druhá vrstva už nepracuje priamo s pixelmi pôvodného obrázka, ale s výstupom prvej vrstvy. Pracuje teda už s abstraktnejšími konceptmi, než sú pôvodné pixely. Ukazuje sa pritom, že čím viac skrytých vrstiev model obsahuje, t. j. čím je hlbší, tým lepší výkon dosahuje (toto pravidlo neplatí vždy, závisí to od kontextu a riešenej úlohy).
Od prelomu A. Krizhevského a jeho spolupracovníkov sa hlboké neurónové siete využívajú čoraz častejšie a neustále sa zlepšujú. Môžu nám pomáhať pri analýze a získavaní poznatkov zo snímok z kamier, vďaka čomu sa napríklad autonómne autá môžu rozhodnúť, či má auto odbočiť alebo pridať plyn, alebo pri analýze tónu diskusie na sociálnych sieťach, čo môže prispieť k jej kultivovaniu a zníženiu množstva nenávistných príspevkov.
Neurónové siete a ich aplikácie už v súčasnosti prekonávajú ľudí vo viacerých individuálnych činnostiach. No aj tu platí výrok: Nič nie je zadarmo. Cenou za narastajúcu využiteľnosť neurónových sietí je okrem iného aj ich komplexnosť.
A s narastajúcou komplexnosťou zároveň klesá naša schopnosť porozumieť modelom a ich rozhodnutiam.

Zakódované vedomosti
Je pravda, že pri niektorých typoch aplikácií nie je nutné takýmto modelom detailne rozumieť. Napríklad nie je až taký veľký problém, ak nám umelá inteligencia v e-shope neodporučí najlepší telefón. Potom sú tu však regulované odvetvia a oblasti ako medicína, bezpečnosť, energetika, financie či už uvedené autonómne vozidlá, ktoré majú priamy a významný dosah na naše životy a v ktorých sú pochopenie a schopnosť vysvetliť to, ako umelá inteligencia premýšľa, rovnako dôležité ako to, aké sú jej výsledky.
Hoci systémy AI a ich využitie sú na vzostupe, v súčasnosti ešte nerozhodujú vo väčšine citlivých prípadov. Kým sa tak stane, budeme musieť byť schopní v dostatočnej miere vedieť odpovedať na otázky ako: Prečo nám systém oddelenia ľudských zdrojov odporúča neprijať zamestnanca? Na základe čoho sa rozhoduje model o tom, či je niekto náchylný zopakovať trestný čin? Ako rozoznajú autonómne vozidlá značku STOP a dokážu ju rozoznať dostatočne dobre? Je pre nás dôležité, aby sme rozumeli tomu, na základe čoho sa rozhodujú a aké poznatky obsahujú neurónové siete?
Zrozumiteľnosť rozhodnutia
Aj v rámci nášho výskumu v Kempelenovom inštitúte inteligentných technológií sa zaoberáme otázkami vysvetliteľnej a interpretovateľnej umelej inteligencie. Vysvetliteľnosť a interpretovateľnosť sú veľmi dôležité pojmy, ktoré však ani vo vedeckej literatúre ešte nemajú ustálený význam.
Vysvetliteľnosť má za úlohu poskytnúť zdôvodnenie rozhodnutia umelej inteligencie v jazyku, ktorému je človek schopný porozumieť. Inými slovami, chceme vedieť, prečo sa model rozhodol tak, ako sa rozhodol. Pri klasifikácii zvierat na obrázkoch napríklad môžeme chcieť zvýrazniť tie časti obrázka, ktoré AI presvedčili, že sa na ňom nachádza mačka alebo pes.
Interpretovateľnosť sa v porovnaní s vysvetliteľnosťou nezameriava na konkrétnu predpoveď, ale jej cieľom je odhaliť a porozumieť poznatkom zakódovaným v modeli. Môže nás napríklad zaujímať, ako si model klasifikujúci obrázky rôznych zvierat predstavuje mačku. Hovoríme o tzv. mapovaní abstraktných konceptov do domény, ktorej človek dokáže porozumieť.
Schopnosť vysvetliť, ako AI dospela ku konkrétnej predpovedi, poskytuje nové možnosti na zlepšenie modelov, objavenie skrytých skreslení, zakódovanej diskriminácie a interpretovanie vedomostí vnútri modelu.
Správnosť vs interpretovateľnosť

Výkonnosť neurónových sietí neprichádza zadarmo. Na to, aby siete dosiahli s pomerne malou námahou (v porovnaní s inými prístupmi) vysokú presnosť, musia byť komplexné. Podobne ako v iných sférach života, aj tu platí, že rozumieť zložitým veciam je oveľa ťažšie ako rozumieť tým jednoduchým. Cieľom nášho výskumu je spojiť presnosť hlbokého učenia s jeho interpretovateľnosťou a vysvetliteľnosťou.
Vo všeobecnosti platí, že čím explicitnejšie je znalosť uchovávaná v modeli a čím viac je tento model interpretovateľný pre človeka, tým menšiu má modelovaciu kapacitu (okrem iného preto, lebo takéto kódovanie znalostí je náročné na prácu človeka) a dosahuje menšiu presnosť. Napríklad v tzv. pravidlových systémoch alebo jednoduchých rozhodovacích stromoch sú myšlienkové pochody modelu v procese rozhodovania krásne jednoduché: AK má zviera perie A nelieta A žije v chladných oblastiach, TAK je to tučniak.
Takéto modely sú však veľmi ťažko použiteľné pri riešení komplikovaných úloh, kde okrem toho môžu ľahko stratiť svoju interpretovateľnosť. Keby sme rovnaký model chceli použiť napríklad na rozpoznanie jazyka, v ktorom je písaný text, počet podmienok v pravidle AK … A … TAK by sa mohol rýchlo vyšplhať na stovky až stovky tisícov.
Hľadanie kompromisov
Napriek tomu, že v súčasnosti sa vo výskume aj v priemysle skloňujú najmä komplexné modely ako hlboké neurónové siete, treba mať na pamäti, že ich bezprecedentná výkonnosť má svoju cenu.
Proces rozhodovania zložitých modelov je netransparentný, čo môže mať v kritických doménach ako zdravotníctvo či finančný sektor vážne dôsledky alebo môže úplne zabrániť použitiu komplexných modelov.
Výskum v oblasti vysvetliteľnej umelej inteligencie (Explainable Artificial Intelligence – XAI) sa usiluje poskytnúť metódy a techniky, aby bolo možné dosiahnuť to najlepšie z oboch svetov, teda zrozumiteľnosť jednoduchých modelov a výkonnosť tých zložitých, ktoré sa často označujú aj ako čierne skrinky.
Martin Tamajka
Kempelenov inštitút inteligentných technológií
Tento článok je súčasťou série Vysvetliteľná umelá inteligencia: od čiernych skriniek k transparentným modelom.
Projekt podporila Nadácia Pontis.
Anglickú verziu článku si môžete prečítať tu.


